目录
RabbitMQ 简介
RabbitMQ 是一个高可靠的消息队列系统(Message Broker),在不同的服务之间异步传输消息,实现系统与系统之间的解耦,在不稳定的流量面前,可以实现稳定的削峰填谷,为系统的可扩展性提供了基础设施。
官网的介绍是:
RabbitMQ is a message broker: it accepts and forwards messages. You can think about it as a post office: when you put the mail that you want posting in a post box, you can be sure that the letter carrier will eventually deliver the mail to your recipient. In this analogy, RabbitMQ is a post box, a post office, and a letter carrier.
可以把它想象成一个邮局系统,写信的人不需要自己把信件送到收信人手上,只需要投递到邮局,RabbitMQ 就扮演了这个邮局的角色。
RabbitMQ 也被称为消息中间件(Message Middleware),因为它的定位是处于各个服务之间,充当消息中枢,并不负责处理业务逻辑,只负责可靠地接收、存储并转发消息,是典型的基础设施组件。
基本概念
RabbitMQ 有以下一些概念:
Producer
生产者,消息的产生来源,业务系统一般担任此角色,负责把消息投递给消息中间件。
Consumer
消费者,消息的处理方,业务系统一般担任此角色,负责从消息中间件中获取消息并进行业务处理。
Queue
队列,就是消息存放的地方,生产者往队列投递信息,消费者从队列取出信息。
Binding 和 Exchange
绑定,就是关联 exchange 和 queue 之间的纽带,在 RabbitMQ 中,producer 并不是直接发 message 发送给 queue,而是先交给 exchange,exchange 根据 binding 规则,以及 message 的路由键(routing key),将 message 路由到对应的 queue 中。
Routing Key 和 Binding Key
routing key,路由键,是由 producer 在发送 message 时,给 message 的一个元信息,目的是告诉 exchange,这条 message 该路由到哪里。
binding key,绑定键,是在创建 exchange 和 queue 之间的 binding 关系时引入的,目的是告诉 exchange,这个 queue 想要接收什么 message。
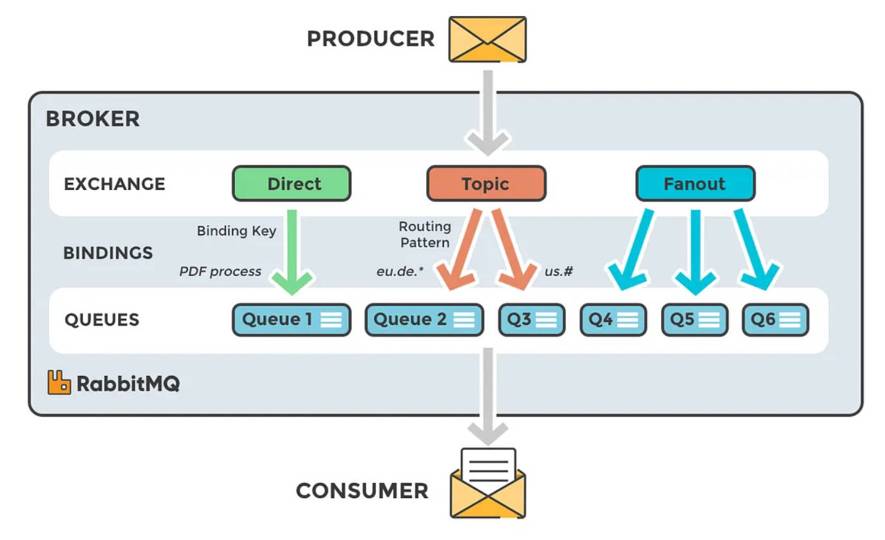
Exchange 有几种类型:
- direct,精确匹配
- fanout,广播
- topic
- headers
下图描述了 RabbitMQ 中,消息在各个组件中的流转:
特点
优势 1:异步
第一个优势是,解耦系统架构,把同步模式改成了异步模式,如果没有消息中间件的情况下,A 需要调用 B 的服务,A 得先知道 B 的地址或者名称(比如服务器地址和接口),通过 HTTP 发起调用,在这一步会阻塞,直到 B 处理完成后,A 才能继续下一步。
引入了消息中间件,A 不需要直接请求 B,A 甚至不需要知道 B 的存在,因为 A 只需要往队列里递交任务就行了,至于消费者 B 可以有一个也可以有多个,A 和 B 可以是完全独立的,用不同语言编写的服务。
优势 2:抗并发
传统模式下,并发量一旦升高,响应速度就会变慢,业务逻辑的处理就会成为系统瓶颈,尤其在很多流量分配不均的场景中,会在某些时刻产生很大的瞬时流量。
消息中间件可以充当缓冲层,大量的瞬时任务可以积压在队列中(能堆积多少,取决于队列所处服务器的内存或磁盘空间),这样消费者不会被瞬间的大流量冲垮,可以按照固定的速率均匀的消费信息和执行任务。
优势 3:扩容和稳定性
传统模式下,如果消费者服务 B 挂了,那么 A 也会跟着报错(无法调用成功),消息队列可以在消费者宕机的情况下,缓存任务,等到消费者服务重新上线后,继续执行宕机期间未完成的任务。
由于使用了异步的模式,当瓶颈出在消费者时,可以迅速拉起多个消费者共同消费一个队列中的任务。
使用场景
无论是异步还是抗住高并发,主要集中在流程耗时这个场景,意味着大部分瓶颈都是在任务消费者服务中,以下单为例,用户下单后,系统需要执行:
- 扣减库存
- 持久化订单信息
- 计算计分
- 发送短信或者邮件
- 根据下单元数据,调用推荐算法
如果所有业务按照顺序执行的话,用户就会在调用下单接口后,进入漫长的等待。
但实际上,只需要把下单信息持久化到数据库,然后往队列里发送下单信息,下游的消费者再按照自己的速率去完成计算和发送通知等耗时的服务。
IO 密集型(爬虫或者电商下单),CPU 密集型(图片压缩或者视频处理),瓶颈都是消费者,生产者如果没有消息队列,那么用户体验或者系统吞吐量会很糟糕。
pika
pika 是 AMQP 0-9-1(也就是 RabbitMQ 支持的协议)的纯 Python 实现。
通过 pika 建立与 RabbitMQ 的连接可以通过 URI 或者参数配置的方式:
credentials = pika.PlainCredentials('your_username', 'your_password')
parameters = pika.ConnectionParameters(
host='your_rabbitmq_host',
virtual_host='study',
credentials=credentials
)
connection = pika.BlockingConnection(parameters)
或者
rabbitmq_uri = 'amqp://your_username:your_password@your_rabbitmq_host:5672/study'
connection = pika.BlockingConnection(pika.URLParameters(rabbitmq_uri))
channel = connection.channel()
通信模式
点对点
点对点是一种最基础的模式,生产者发送消息到队列,一个队列可以有一个或者多个消费者监听,但一条消息只会被其中一个消费者处理(竞争消费)。
这里用默认 exchange (Default Exchange 或者叫匿名 Exchange,Anonymous Exchange)演示点对点的生产消费模型。
默认 exchange 是 RabbitMQ 自带的一个 exchange,当你安装并启动 RabbitMQ 后,系统会自动为每个 VHost 创建一个名称为空字符串 "" 的 Direct Exchange。
它的存在就是方便你不用手动创建一个 direct 类型的 exchange,使用匿名 Exchange 时,producer 生产的消息的
routing_key
就等于队列名。
所有的队列(Queue)在创建后,都会自动绑定到这个默认交换机上,并且绑定的 Routing Key 与队列的名称完全一致。
比如创建一个名为
test_queue
的队列,RabbitMQ 会自动将该队列绑定到名为 "" 的 exchange,当你往 RabbitMQ 发送消息时,不指定 exchange 名称(设为空字符串),RabbitMQ 就会找到默认交换机,默认交换机通过你给这条消息设置的
routing_key
,匹配(字符完全匹配)到同名的队列,把消息投递出去。
首先编写一个 producer:
# 声明一个叫 task_queue 的持久化队列,MQ 重启后该 queue 依然存在
channel.queue_declare(queue='task_queue', durable=True)
# 发送的消息,为了清楚这一条消息后续被哪一个 consumer 消费,这里设置一个随机的 suffix
message = f"Task-{random.randint(1, 100)}"
# 发送消息
channel.basic_publish(
# exchange 设置为空字符串,表示使用匿名 exchange
exchange='',
# 消息的 routing key
routing_key='task_queue',
body=message,
# delivery mode = 2 表示消息持久化,消息写入磁盘
properties=pika.BasicProperties(
delivery_mode=2,
)
)
print(f" [x] Sent '{message}'")
connection.close()
这个 producer 做的事情很简单,声明了一个队列,并且发送了一条消息给默认 exchange,默认 exchange 会把这条
routing_key
为
task_queue
的消息,投递给名为
task_queue
的队列。
接下来编写一个 consumer 来消费信息:
channel.queue_declare(queue='task_queue', durable=True)
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
# 模拟耗时操作
time.sleep(1)
print(" [x] Done")
# 手动发送 ACK 应答,告知 MQ 消息已处理完,可以删除了
ch.basic_ack(delivery_tag=method.delivery_tag)
# 公平分发:告诉 RabbitMQ 在消费者处理完当前消息前,不要发新消息给它
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
可以在三个终端,开启三个 consumer,这意味着一个
task_queue
被创建,并且三个 consumer 准备消费这个队列。
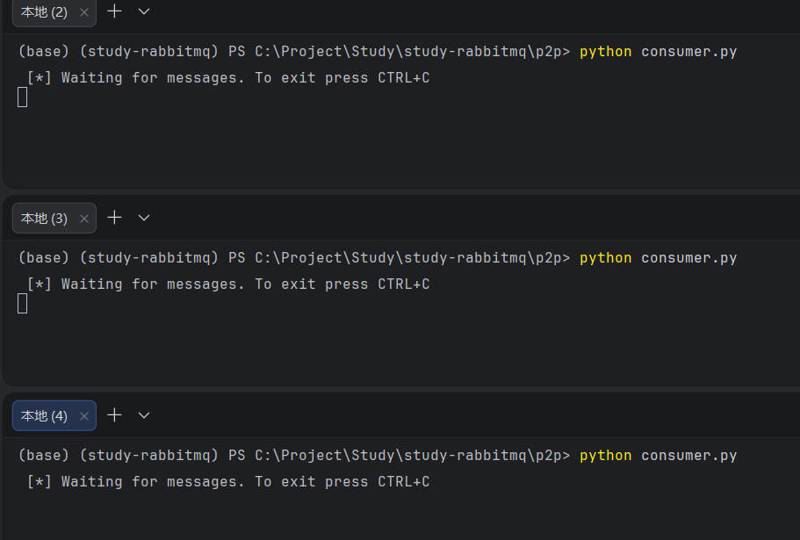
通过 rabbitmqctl 可以在 rabbitmq-server 上看到有几个 consumer:
-p study
表示查看 vhost 为 study 下的内容,如果不指定
-p
则查看默认 vhost('/')。
koril@ali-djhx-debian-2:~$ sudo rabbitmqctl -p study list_consumers | column -t
Listing consumers in vhost study ...
queue_name channel_pid consumer_tag ack_required prefetch_count active arguments
task_queue <rabbit@ali-djhx-debian-2.1773799380.32377.0> ctag1.83d85df1df38404c89c426376d9e23c9 true 1 true []
task_queue <rabbit@ali-djhx-debian-2.1773799380.32362.0> ctag1.5fa193192d9146c59cba601381ec17d1 true 1 true []
task_queue <rabbit@ali-djhx-debian-2.1773799380.32348.0> ctag1.25aa027c5a9140f5a431157b27c89939 true 1 true []
接下来启动生产者,可以看到每运行一次生产者代码,就意味着往队列里发送了一条信息,并且只会被三个 consumer 中的某一个进行消费。
可以通过 rabbitmqctl 查看消费过程中的
messages_ready
、
messages_unacknowledged
、messages、consumers 等信息:
sudo rabbitmqctl -p study list_queues name messages_ready messages_unacknowledged messages consumers | column -t
-
messages_ready:等待消费的消息 -
messages_unacknowledged:已分发但未 ack 的消息 - messages: 队列中的消息总数(Ready + Unacked)
- consumers: 消费者数量
可以通过 Linux 命令
watch
来进行实时监控,可以在 producer 中,写一个循环,一口气往队列塞入 n 条信息:
def publish_msg():
message = f"Task-{random.randint(1, 100)}"
# 发送消息
channel.basic_publish(
# 匿名队列
exchange='',
# 消息的 routing key
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2,
)
)
print(f" [x] Sent '{message}'")
n = 100
for i in range(n):
publish_msg()
然后启动监控命令:
watch -n 1 "sudo rabbitmqctl -p study list_queues name messages_ready messages_unacknowledged messages consumers | column -t"
可以看到三个消费者不断的消费任务,
messages_ready
和 messages 的数值每隔一秒降低 3 个点,
messages_unacknowledged
维持在 3(因为我启动了三个消费者),可以试着把其中一两个消费者停掉,或者在启动新的消费者,观察数值的变化。
消费者里的
channel.basic_qos(prefetch_count=1)
作用是限制一个 channel 最大的 unack message 数量,相当于告诉在我(consumer)没还给你(ACK)足够多的消息之前,别再给我发新的任务。
每个消费者的 unack message 数量可以通过以下命令查看:
sudo rabbitmqctl -p study list_channels name consumer_count messages_unacknowledged
设置了
basic_qos
有很多好处,不设置的话,会导致以下一些问题:
- RabbitMQ 会尽可能快地把队列里的所有消息都发给消费者,而消费者处理的速度如果很慢,会导致占用内存会飙升。
- 在有多个 consumer 的情况下,有的 consumer 因为启动的较早,所有消息都推给了它,有些启动晚的,获取不到消息,导致有的非常忙碌,有的很闲,无法充分利用资源。
换句话说,保证了 consumer 每次只取一条信息去处理,如果要提高单个 consumer 的吞吐量,可以增大该值。
假如 task 是耗时的任务,尤其是 IO 密集型,可以使用 ThreadPoolExecutor,把耗时的任务放到线程池里执行。
上面的
consumer.py
把耗时的任务(这里是用
time.sleep
模拟)直接放在 callback 里面,导致主线程被耗时任务阻塞,以下是线程池并发处理多个任务的写法:
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
MAX_WORKER_NUM = 10
MAX_PREFETCH_NUM = MAX_WORKER_NUM // 2
executor = ThreadPoolExecutor(max_workers=MAX_WORKER_NUM)
def ack_message(ch, delivery_tag):
"""回到主线程执行的 ACK"""
if ch.is_open:
ch.basic_ack(delivery_tag)
print(f" [v] Msg {delivery_tag} ACKed")
else:
print('通道已关闭,无法 ACK')
def process_message(body):
print(f"[Thread {threading.get_ident()}] Processing {body.decode()}")
time.sleep(1)
print(f"[Thread {threading.get_ident()}] Done")
def callback(ch, method, properties, body):
delivery_tag = method.delivery_tag
future = executor.submit(process_message, body)
# 处理完成后再 ack(回到主线程执行)
def on_done(fut):
# 通过 add_callback_threadsafe 切回 pika 主线程
ch.connection.add_callback_threadsafe(
lambda: ack_message(ch, delivery_tag)
)
future.add_done_callback(on_done)
# 公平分发:告诉 RabbitMQ 在消费者处理完当前消息前,不要发新消息给它
channel.basic_qos(prefetch_count=MAX_PREFETCH_NUM)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
print(f' [*] Waiting for messages. To exit press CTRL+C, prefetch count: {MAX_PREFETCH_NUM}, pool size: {MAX_WORKER_NUM}')
channel.start_consuming()
广播
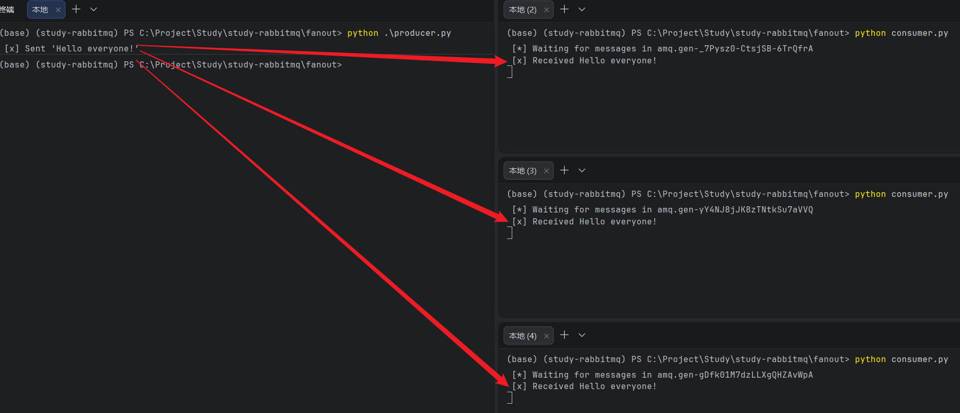
点点对的模式适用于一个消息只被其中一个消费者消费,如果想要所有消费者消费同一个信息,那就需要使用广播(fanout)。
producer 这里不再使用默认 exchange,而是需要显式声明一个类型为 fanout 的 exchange:
channel = connection.channel()
channel.exchange_declare(
exchange='task_exchange',
exchange_type='fanout'
)
message = "Hello everyone!"
channel.basic_publish(
exchange='task_exchange',
# fanout 下的 routing_key 会被 rabbitmq 忽略
routing_key='',
body=message
)
print(f" [x] Sent '{message}'")
connection.close()
consumer 用的是临时队列(不需要持久化,而且名字随机),一个 consumer 对应一个临时队列:
channel = connection.channel()
channel.exchange_declare(
exchange='task_exchange',
exchange_type='fanout'
)
result = channel.queue_declare(
# 空字符串 → RabbitMQ 自动生成一个随机名称
queue='',
# 连接断开自动删除队列
exclusive=True
)
queue_name = result.method.queue
# 绑定队列到 exchange
channel.queue_bind(
exchange='task_exchange',
queue=queue_name
)
print(f" [*] Waiting for messages in {queue_name}")
def callback(ch, method, properties, body):
print(f" [x] Received {body.decode()}")
channel.basic_consume(
queue=queue_name,
on_message_callback=callback,
auto_ack=True
)
channel.start_consuming()
启动三个 consumer,再执行一次 producer 发布一条消息,效果如下:
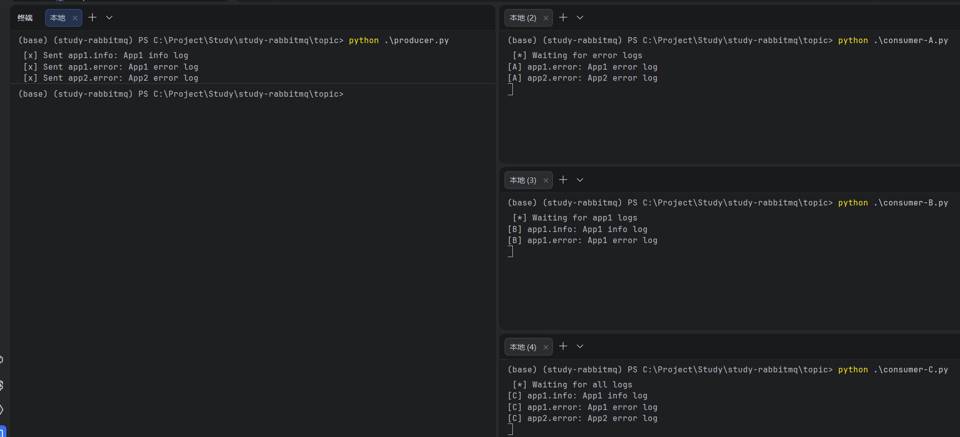
通配符模式
对于消息投递的范围来说,direct 类型太固定,fanout 又太宽泛,如果要寻找一种类似 Unix 通配符模式的匹配规则,那么 RabbitMQ 的
topic
类型 exchange 就是最好的选择。
topic exchange 不只是简单的比较字符串,它支持模式匹配,发送消息时需要携带一个
routing_key
,而队列绑定到交换机时使用
binding_key
。
binding_key
支持两种通配符:
-
*:匹配一个单词 -
#:匹配零个或者多个单词
routing_key
必须是点号分隔的单词列表,比如:
-
auth.info -
log.error -
shop.stock.sold
producer 这里发送三种不同
routing_key
的 message 给一个名为
task_exchange
,类型是 topic 的 exchange:
channel = connection.channel()
channel.exchange_declare(
exchange='task_exchange',
exchange_type='topic'
)
def publish(routing_key, message):
channel.basic_publish(
exchange='task_exchange',
routing_key=routing_key,
body=message
)
print(f" [x] Sent {routing_key}: {message}")
if __name__ == '__main__':
publish("app1.info", "App1 info log")
publish("app1.error", "App1 error log")
publish("app2.error", "App2 error log")
connection.close()
consumer-A,consumer-B,consumer-C 分别消费不同类型的消息,通过
binding_key
的通配符实现和 exchange 绑定。
consumer-A:
channel = connection.channel()
channel.exchange_declare(
exchange='task_exchange',
exchange_type='topic'
)
# 临时队列
result = channel.queue_declare('', exclusive=True)
queue_name = result.method.queue
# 绑定规则
channel.queue_bind(
exchange='task_exchange',
queue=queue_name,
routing_key='*.error'
)
print(" [*] Waiting for error logs")
def callback(ch, method, properties, body):
print(f"[A] {method.routing_key}: {body.decode()}")
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
consumer-B:
channel = connection.channel()
channel.exchange_declare(
exchange='task_exchange',
exchange_type='topic'
)
# 临时队列
result = channel.queue_declare('', exclusive=True)
queue_name = result.method.queue
# 绑定规则
channel.queue_bind(
exchange='task_exchange',
queue=queue_name,
routing_key='app1.*'
)
print(" [*] Waiting for app1 logs")
def callback(ch, method, properties, body):
print(f"[B] {method.routing_key}: {body.decode()}")
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
consumer-C:
channel = connection.channel()
channel.exchange_declare(
exchange='task_exchange',
exchange_type='topic'
)
# 临时队列
result = channel.queue_declare('', exclusive=True)
queue_name = result.method.queue
# 绑定规则
channel.queue_bind(
exchange='task_exchange',
queue=queue_name,
routing_key='#'
)
print(" [*] Waiting for all logs")
def callback(ch, method, properties, body):
print(f"[C] {method.routing_key}: {body.decode()}")
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
效果如下: